CoreDX DDS Centralized Discovery
Unmatched Scalability, even in Embedded Environments
The automatic discovery process is one of the more powerful and useful features of CoreDX DDS. Automatic discovery of entities allows CoreDX DDS applications to publish and subscribe to data without needing to configure the endpoint(s) they talk to. Whether these endpoints are on the same machine, or across the room, CoreDX DDS applications do not need any knowledge of the other applications they will be communicating with.

Overview
The Standard (peer-to-peer) Discovery process in CoreDX DDS is encapsulated in every CoreDX DDS application, and does not require any additional daemons or services. Each CoreDX DDS application performs the discovery process, including announcing the presence of its DDS Entities, listening for other DDS Entities, and looking for matches between its own DDS Entities and those discovered. The standard discovery mechanism is interoperable between DDS implementations.
This Standard Discovery is depicted in the below diagram.
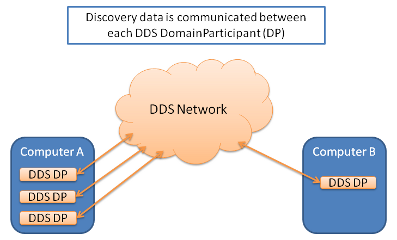
Despite the many benefits of the Standard Discovery mechanism, it does have some drawbacks for certain system architectures. In particular, Standard Discovery may not scale well to large DDS domains. In DDS 150 domains with large numbers of DDS entities (Participants, Readers or Writers), the Standard Discovery mechanism can require large amounts of memory as every Participant discovers all other entities in the system. In many case, this ‘world view’ of the DDS domain is wasteful. Often, a Participant is required to communicate with only a small sub-set of the entire DDS network.
To address the scalability issues of Standard Discovery, CoreDX DDS supports a specialized discovery mechanism called Centralized Discovery. CoreDX Centralized Discovery performs the work of discovering all DDS Entities and appropriately communicating those entities to participants based on ‘need to know’. The Centralized Discovery mechanism can scale to
very large DDS domains, without the explosion of memory allocation found in Standard Discovery.
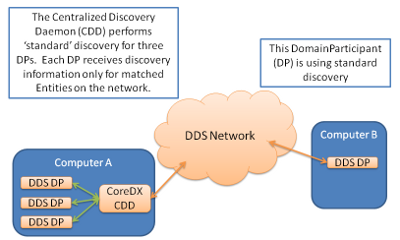
Further, Centralized Discovery is designed to be interoperable with Standard Discovery. This means that a DDS domain may combine both discovery mechanisms as necessary: some Domain Participants can use Standard Discovery while others use Centralized Discovery. This Centralized Discovery is depicted in the below diagram.
Memory Utilization and Scalability
With Standard Discovery, each DomainParticipant learns and remembers every active DomainParticipant, DataReader, and DataWriter in the DDS Domain. As the number of DDS Entities in the Domain grows, so does the amount of discovery information stored in each DomainParticipant.
For systems that contain many DDS Entities, it may be desirable to reduce the number of copies of this maintained discovery information. This is the benefit of Centralized Discovery. The discovery information about all DDS Entities in a DDS Domain is stored in a centralized location, reducing the overall memory utilization in the system.
The Centralized Discovery Daemon determines the potential Reader/Writer matches for all its connected DomainParticipants. DomainParticipants learn only about potential matches from the Centralized Discovery Daemon. A CoreDX Centralized Discovery Daemon must reside on the same machine as DomainParticipants that are configured to use Centralized Discovery.
Therefore, the greatest benefits for memory reduction are seen when:
- 1. There are many DDS Entities on one machine that can use Centralized
Discovery, and - 2. For each DomainParticipant, a small percentage of the DDS Entities in
the DDS domain match with its own DDS Entities.
Deployment of Centralized Discovery
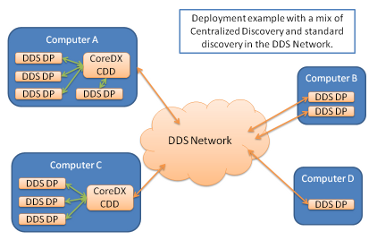
A CoreDX Centralized Discovery Daemon must be deployed on each computer that is hosting a DomainParticipant configured to use Centralized Discovery. There should be only one CoreDX Centralized Discovery Daemon running on a computer. Computers that are not hosting DomainParticipants configured to use Centralized Discovery do not need a CoreDX Centralized Discovery Daemon.
An example deployment using Centralized Discovery is shown below.